How to Download Files From URL Made Easy

Grabbing a file from a URL can be as simple as a right-click or as complex as a custom-coded script. You might just need to save a PDF from a link, but you could also be automating a massive data pull. The best method really boils down to what you're trying to accomplish.
For the simplest tasks, your browser is all you need. Just right-click a link and hit "Save Link As." But when you need more power—say, for downloading multiple files at once or handling more complex jobs—you'll want to look at browser extensions or even command-line tools like Wget.
Your Quick Guide to Downloading Files From a URL
Before we dive into the step-by-step guides, let's get a bird's-eye view. Choosing the right tool from the start saves a ton of headaches later. A casual user grabbing a report has completely different needs than a developer building a data pipeline.
This visual breakdown gives you a great sense of which tool fits which job, matching the method to the user and their specific goal.
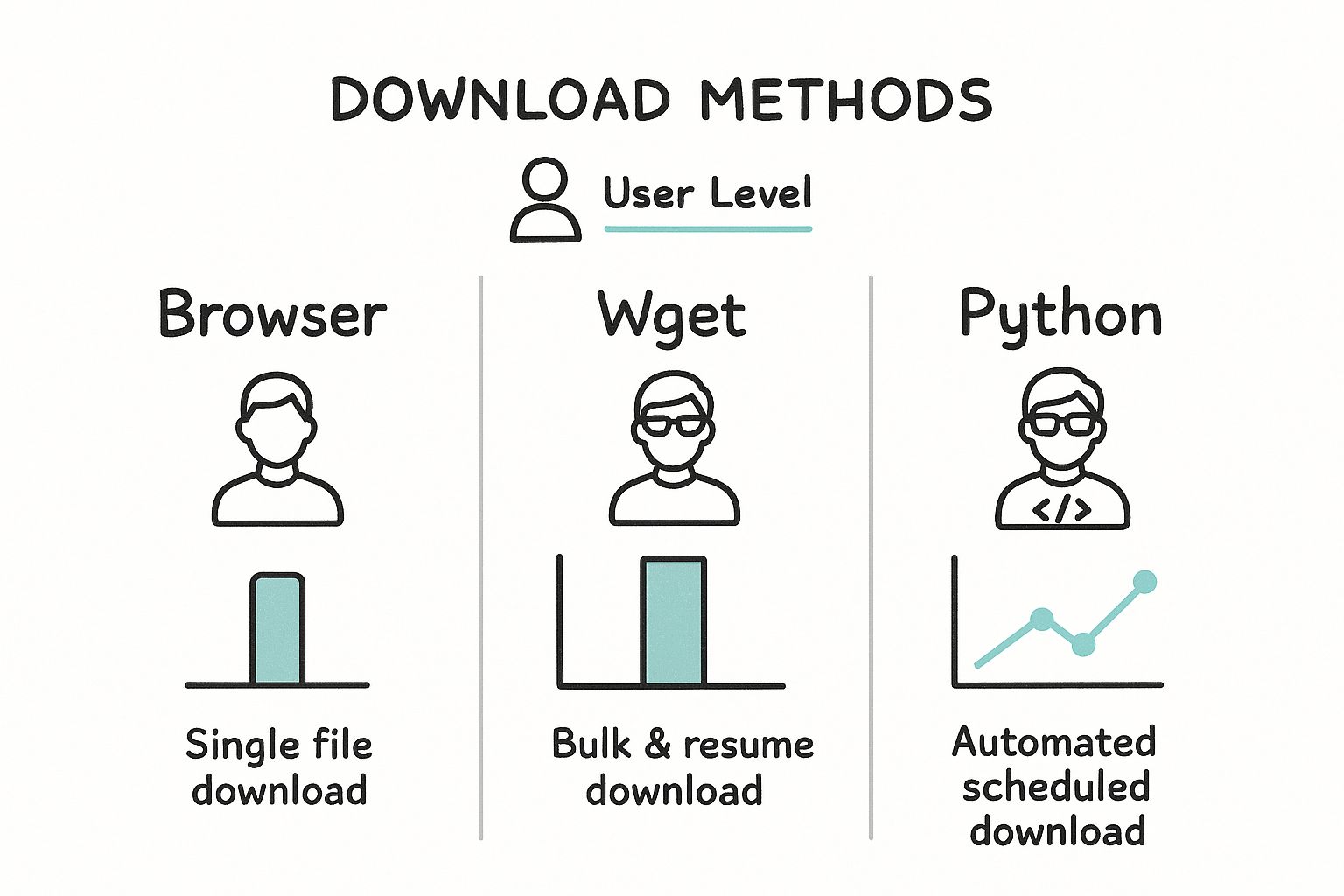
As you can see, the options range from the straightforward browser download all the way to a fully automated Python script. The more control and automation you need, the more technical the tool becomes.
Why Efficient Downloads Matter
The sheer volume of files being downloaded today is staggering, especially on mobile devices. Global mobile app downloads have skyrocketed to 218 billion and are expected to keep climbing by 8% each year. This boom is fueled by faster 5G networks and our daily habits—the average person uses around 30 different apps every month, all of which need updates and new content fetched from a URL.
Gaming apps are a huge piece of this puzzle, accounting for 56% of all downloads. Think about it: that's a massive amount of data being transferred from servers to devices worldwide. You can explore the full research on these app download trends to get a better sense of the scale.
No matter which tool you use, the underlying process is the same. You're just sending a request to a server, asking for a specific file. The method you choose is simply the wrapper around that request and how you handle the server's response.
Choosing Your File Download Method
To help you zero in on the right tool for your specific task, I've put together a quick comparison table. This breaks down the four main approaches, from a simple click to a fully automated script.
| Method | Best For | Skill Level | Example Use Case | | :--- | :--- | :--- | :--- | | Browser (Manual) | Quick, one-off downloads of single files | Beginner | Saving a PDF report or an image from a website. | | Browser Extension | Downloading multiple files from a single page | Beginner | Grabbing all images or documents from a gallery or list. | | Command-Line (Wget/cURL) | Bulk downloads, resuming interrupted files, mirroring sites | Intermediate | Downloading an entire dataset or backing up a website. | | Programming (Python) | Custom logic, automation, API integration, scheduling | Advanced | Building a scraper to download specific files from multiple pages on a schedule. |
Ultimately, the best approach depends on a few key factors: how many files you need, how often you need them, and how much control you want over the process.
With these different methods in mind, you can pick the one that fits your needs perfectly, whether it’s for a one-time download or a recurring, automated workflow.
Grabbing Files Straight From Your Web Browser
Most of the time, the simplest way to download a file from a URL is right in your web browser. We all know the classic "right-click and save," but that's just scratching the surface. When you need to grab more than just one file, modern browsers and a few smart extensions can give you some serious power.
Think about the last time you wanted to save an entire photo gallery from a travel blog or a dozen PDF reports from a research site. Clicking each link one by one is a surefire way to waste your afternoon. This is where a good browser extension comes in, turning that tedious chore into a quick, one-click job.
This browser-first approach is more relevant than ever. With mobile devices now driving 62.54% of all global website traffic, the way we access and save content has shifted dramatically. For most people, a simple, browser-based solution is the most convenient and accessible option. You can dig into the impact of mobile traffic trends on Statista for more context.
Supercharge Your Browser With Extensions
Browser extensions are basically mini-apps that add new features directly into your browser. For downloading files, they can completely change the game, giving you capabilities that you’d normally only find in standalone desktop software. They’re perfect for anyone who wants more control without having to learn a new, complex program.
I've used dozens over the years, but a few have consistently stood out:
- Video DownloadHelper (Chrome & Firefox): My go-to for grabbing embedded videos from sites where there's no obvious download link. It just works on a massive variety of pages.
- DownThemAll! (Firefox): This one's a classic for a reason. It’s a powerful manager that lets you download all the links or images on a page at once, and it has great filtering and renaming options to keep things organized.
- Simple Mass Downloader (Chrome): If you just have a list of URLs and want to download them all in a batch, this is a fantastic, lightweight choice.
Once installed, these tools usually add a small button to your browser’s toolbar. When you land on a page with lots of files, you just click the button, select what you want from the list, and let it do the work.
The real magic of a good browser download manager is its ability to queue everything up. It handles all the files for you, so you can set it and forget it instead of babysitting each individual download.
Key Features of Browser Download Managers
A solid download manager extension offers a whole suite of features that go way beyond what your browser can do on its own. They provide a much more robust and organized workflow for handling downloads.
Here’s what you should look for:
- Pause and Resume: This is a lifesaver. If a massive download gets interrupted by a spotty Wi-Fi connection, you can often pick it up right where it left off instead of starting from scratch.
- Bulk Downloading: The core feature. Being able to select all the PDFs or JPGs on a page and grab them with a single click is a huge time-saver.
- Filtering Options: You can set up rules to only download files that meet certain criteria, like file type (e.g., only
.zipfiles) or even keywords in the URL. - Smart Organization: Many extensions can automatically save files into different folders based on the website they came from or their file type. This feature alone helps keep my downloads folder from becoming a total mess.
With these simple but powerful tools, you can handle just about any download task you can think of, all without ever leaving your web browser.
Taking Control with Command-Line Tools
When your download needs go beyond what a browser can handle, the command line is your best friend. For anyone who needs more power, automation, and sheer control, tools like Wget and cURL are legendary for a reason. They’re the daily drivers for developers and sysadmins, but they are surprisingly accessible for anyone looking to download files from a url efficiently.
Think about it: have you ever needed to grab an entire dataset made up of hundreds of individual files? Or maybe you wanted to mirror a whole website for offline browsing. These are the kinds of jobs where clicking "Save As" a hundred times just isn't an option. The command line shines in these scenarios, offering a rock-solid way to manage serious download tasks.
The need for powerful tools isn't just a niche developer problem. We're all dealing with a massive amount of data. In fact, the total global data volume is expected to reach 181 zettabytes next year. That's a staggering figure, and it highlights why having efficient download methods is essential. If you're interested in the numbers behind this trend, Rivery.io has some great insights on big data statistics.
Your Go-To Tools: Wget and cURL
Chances are, you already have these tools. Both Wget and cURL come standard on most Linux and macOS systems. Windows users can easily get them up and running with the Windows Subsystem for Linux (WSL) or a package manager like Chocolatey.
So, what's the difference?
- Wget is the workhorse for pure downloading. Its superpower is recursive downloads, meaning it can crawl and download entire website directories with a single command. It just gets the job done.
- cURL is more of a Swiss Army knife for data transfer. It handles a huge range of protocols, not just HTTP, making it perfect for things like testing APIs or dealing with complex server authentication.
The official cURL website is a great resource, and honestly, it’s a perfect reflection of the tool itself—functional, information-dense, and no-nonsense.
A Few Practical Recipes for the Terminal
Let's dive into some real-world examples. These are simple, one-line commands that solve common (and often frustrating) download challenges. You can copy and paste these directly into your terminal.
Resume a Huge Download That Got Interrupted
Nothing is worse than a massive download failing at 99%. With Wget, you don't have to start over. The -c flag tells it to "continue" right where it left off.
wget -c https://example.com/large-dataset.zip
Follow a Redirect to Get the Actual File
Sometimes a download link bounces you to a different URL. The -L flag tells cURL to follow that trail of redirects until it finds the final file. The -o flag lets you name the output file.
curl -L -o my-document.pdf https://example.com/redirecting-link
The real power of the command line comes from automation. You can stitch these simple commands into scripts to handle repetitive downloads, saving yourself a ton of time and effort down the road.
Download from a Password-Protected Site
Need to pull a file from a server that requires a login? Both tools handle basic authentication easily. Here’s how you do it with cURL.
curl -u username:password -O https://example.com/protected/file.dat
The -u flag passes your credentials, and the capital -O flag is a handy shortcut that saves the file using its original name from the server. These commands might look intimidating at first, but they quickly become an indispensable part of your toolkit.
Automating Downloads with Python Scripts
When you need more than just a one-off download, it’s time to bring in the heavy hitters. For anyone who needs to programmatically download files from a url—developers, data scientists, or even just power users—a Python script offers incredible flexibility and control.
Instead of manually clicking links or typing out terminal commands, you can write a script that fetches files for you on a schedule. This is perfect for tasks like grabbing daily financial reports from a public API, archiving web content, or pulling down datasets for a machine learning project. The magic behind this is a simple but powerful library called requests.
The requests library is pretty much the gold standard for making HTTP requests in Python. Its clean, intuitive API is why it’s so popular.

A quick look at its PyPI page shows it’s one of the most downloaded Python packages of all time. That’s a serious stamp of approval from the developer community, and it speaks volumes about its reliability.
Building a Smart Download Script
A basic script is easy, but a robust one needs to anticipate real-world problems. What if you’re trying to download a massive file, like a gigabyte-sized video or a huge data archive? Loading it all into memory at once is a classic way to crash your program. A smart script also needs to handle network hiccups, like a 404 Not Found error if the file has been moved or deleted.
Let's walk through how to build a script that tackles these common issues head-on. Our script will:
- Stream large files: By reading the file in small, manageable chunks, we can download massive files without eating up all our system's memory. This is non-negotiable for performance and stability.
- Check for errors first: Before we even start downloading, the script will confirm the server sent back a successful response (a status code of 200). No point in trying to save a file that isn't there.
- Save the file locally: It will write the downloaded chunks directly to a local file, assembling them piece by piece.
- Provide useful feedback: We’ll add simple
printstatements so we know what’s happening during the download process.
This approach turns a simple download function into a reliable tool you can trust in a production environment.
The real advantage of scripting isn't just automation; it's resilience. A well-written script can anticipate problems—like a server being temporarily down—and handle them gracefully, whereas a manual download would just fail.
A Practical Code Example
Here’s a complete, well-commented Python script using the requests library. It’s a solid foundation you can copy, paste, and adapt for your own projects.
First, you’ll need to install the library. Just open your terminal and run pip install requests.
import requests
def download_file_from_url(url, local_filename): """ Downloads a file from a URL efficiently by streaming its content. Handles potential HTTP errors and saves the file locally. """ try: # Use stream=True to avoid loading the whole file into memory at once with requests.get(url, stream=True) as r: # Check if the request was successful before proceeding r.raise_for_status()
# Open the local file in write-binary mode to save the content
with open(local_filename, 'wb') as f:
print(f"Downloading {local_filename}...")
# Download the file in chunks of 8KB (a good default)
for chunk in r.iter_content(chunk_size=8192):
f.write(chunk)
print(f"Successfully downloaded {local_filename}")
except requests.exceptions.RequestException as e:
# Catch any network-related errors (e.g., connection, timeout)
print(f"An error occurred: {e}")
--- Example Usage ---
URL of a sample image file to download
file_url = 'https://cdn.outrank.so/462429d2-c40c-47a8-a95a-60b03aafc5b5/8e784e30-1a2b-4651-876c-62efd67f0d92.jpg'
The name we want to save the file as on our computer
output_filename = 'downloaded_image.jpg'
Call the function to kick off the download
download_file_from_url(file_url, output_filename)
This code snippet isn't just theory—it’s a practical tool. Imagine you need to download daily weather data CSV files from a government website. You could wrap this logic in a loop that generates the correct URL for each day, automating your entire data collection workflow with just a few more lines of code. That's the true power of scripting your downloads.
How to Fix Common Download Problems
https://www.youtube.com/embed/gYJa3EwCnT8
Even with the right tools in hand, trying to download files from a url can sometimes feel like a game of chance. Downloads fail. Links break. Servers get moody. It happens. The good news is that most of these roadblocks are pretty simple to navigate once you know what you’re looking for.
When a download goes sideways, the first thing to look at is the error message. These aren't just random strings of text; they’re clues that point directly to the source of the problem. Learning to read them is the fastest way to get your download back on track.
Decoding Common HTTP Error Codes
We've all run into a 404 Not Found error. This one is usually straightforward: the URL you have is either wrong or points to something that isn't there anymore. Always start by double-checking the URL for typos. If that's not the issue, the file was likely moved or deleted, and you'll have to hunt for a new link.
The 403 Forbidden error is a different beast entirely. It means you’ve successfully reached the server, but it’s actively refusing to give you the file. You've knocked on the right door, but the bouncer won't let you in.
This usually boils down to a few common scenarios:
- You aren't logged in. Many websites require you to have an account and be logged in before you can access their files. Just sign in and try the URL again.
- Your IP address is blocked. Sometimes servers block IPs from certain regions or those flagged for unusual behavior.
- The server expects a standard browser. In rare cases, a server might be configured to reject requests that don't come from a typical web browser.
A 403 error is all about permissions, not a dead link. Before you throw in the towel, always try logging into the website first. You'd be surprised how often that's the only thing standing in your way.
Tackling Failed or Incomplete Downloads
Nothing is more frustrating than watching a large file download fail when it's almost finished. This is almost always caused by a flaky internet connection. Even a brief drop can sever the connection to the server and kill your progress.
This is where a command-line tool like Wget becomes an absolute lifesaver. If you're downloading a 2GB file in your browser and it fails at the 90% mark, you have to start from scratch. Painful. But with Wget, you can just add the -c (continue) flag.
For example, if your download was interrupted, you'd just run this command: wget -c https://example.com/very-large-file.zip
Wget is smart enough to see what you've already downloaded and will simply pick up right where it left off. This one feature alone makes it essential for anyone who deals with large files and needs a process that can survive a network hiccup.
Common Questions I Hear About Downloading Files
Even with the best tools, you're bound to run into some tricky situations when downloading files from a URL. Let's tackle some of the most common questions that pop up.
Is It Actually Legal to Download Any File I Find?
This is a big one, and the short answer is no, it's not always legal. You absolutely need to have the right or explicit permission from the copyright holder to download and use their content.
Grabbing copyrighted material like movies, software, or ebooks without paying for them is a fast track to legal trouble in most places. Before you download, always look for a "Terms of Service" page, a license agreement, or any copyright notices on the site.
For those of you using automated tools, it's a smart habit to check the site's robots.txt file first. This little text file tells automated software which parts of a site are off-limits. When in doubt, just stick to reputable sources that clearly state their content is for public use.
How Do I Download a Ton of Files from a Long List of URLs?
If you're staring down a massive list of links, clicking "Save As..." on each one is a nightmare. This is where you need to bring in the heavy hitters: command-line tools.
-
My Go-To Method: Wget: Honestly, this is my favorite tool for bulk jobs because it's so straightforward. Just dump all your URLs into a plain text file, one URL per line. Then, pop open your terminal and run this simple command:
wget -i your-list.txt. Wget will take it from there, methodically downloading every single file on your list. -
For More Control: A Script: When things get complicated, a Python script gives you total control. You can write a simple loop to go through your list of URLs and use the
requestslibrary to download each file. The real power here is adding your own logic—like renaming files on the fly or handling specific errors without stopping the whole process.
People often ask about the difference between Wget and cURL. Think of it this way: Wget is a specialized tool built for one job—downloading files and mirroring entire websites recursively. cURL, on the other hand, is like a Swiss Army knife for data transfer. It supports a huge range of protocols beyond just HTTP, which makes it perfect for interacting with APIs or complex server tasks.
My Download Is Crawling. What Can I Do to Speed It Up?
A painfully slow download is usually caused by one of two culprits: your own internet connection or a sluggish server on the other end. But before you give up, there are a few tricks you can try.
Sometimes, a good browser download manager extension can work wonders. These tools often speed things up by opening multiple connections to the server at once, essentially downloading different pieces of the file in parallel and stitching them together at the end.
You could also try downloading during off-peak hours when the server isn't getting hammered with traffic. And finally, do a quick check to make sure no one else on your network is hogging all the bandwidth by streaming 4K video or getting into an intense online gaming session.
Ready to make saving web content effortless and private? Feedforward Software offers Website Downloader, a Chrome extension that lets you download any webpage with a single click for offline access. Get started with Website Downloader today!
Article created using Outrank
Found this helpful?