How to Clone a Site A Practical Guide

At its core, cloning a site is all about creating an offline copy for development, testing, or simply as a personal backup. You can go the old-school route by manually saving the HTML, CSS, and JavaScript files straight from your browser, or you can use a slick browser extension like Website Downloader to get it done in a single click.
Why And When To Clone A Website

Before we jump into the "how," let's talk about the "why." Learning to clone a site isn't about swiping someone's hard work. It's a fundamental skill for web pros, marketers, and even students who need a local version of a site for legitimate reasons.
Think of it this way: developers often clone a live site to create a safe staging environment. This offline copy lets them test updates, play with new features, or squash bugs without any danger of breaking the actual live website. It's a professional safety net.
Legitimate Use Cases For Site Cloning
Designers and marketers get a ton of value out of this, too. A designer might clone a competitor's site to get a closer look at its layout and UI for inspiration. A marketer could grab an offline version to prep for a presentation or to have a static copy for in-depth competitor analysis.
Here are some of the most common and completely ethical reasons you'd want to clone a site:
- Creating Development Environments: Test new code, plugins, or design changes in a secure, offline space before you deploy them.
- Website Migration: Make moving a site between hosting providers way less stressful by working with a local copy first.
- Personal Backups: Keep a full, working backup of your own website. It’s peace of mind for disaster recovery.
- Offline Access: Save crucial articles, documentation, or other resources to look at when you’re not connected to the internet.
Deciding between a manual download and an automated tool often comes down to your technical comfort level and how much time you want to spend.
Cloning Methods At A Glance
Here’s a quick comparison to help you choose the right approach for your needs.
| Method | Best For | Technical Skill Required | Key Benefit | | :--- | :--- | :--- | :--- | | Manual Download | Small, simple sites or learning the basics of web structure. | Basic (understanding file structures helps). | Complete control over which files you save. | | Website Downloader Extension | Complex sites, saving time, or cloning multiple pages quickly. | Minimal (just click a button). | Fast, automated, and preserves the site's structure. |
Both methods have their place, but for most day-to-day tasks, an extension is going to be your most efficient option.
The Growing Importance Of Web Data
The ability to save web content—a practice often called web scraping—is becoming more valuable every day. This is fueled by a huge demand for real-time competitive insights. In fact, the web scraping market is on track to be worth up to $3.5 billion by 2025, with the alternative data market hitting nearly $4.9 billion. You can dig into more web scraping stats and trends over at Scrapingdog. This just shows how important it is to be able to gather and analyze web data effectively.
Key Takeaway: Website cloning is a powerful tool for learning, development, and preservation. The goal is to use it responsibly for tasks like creating backups, setting up testing environments, or analyzing site structure—not for plagiarism or intellectual property theft.
This guide will walk you through the practical steps, giving you the knowledge to handle these tasks the right way. For more tips on web tools and techniques, feel free to check out the other guides on the Website Downloader blog.
The Manual Method: Saving a Site Piece by Piece
If you're the kind of person who likes to get their hands dirty and really understand how things work, the manual method is for you. It’s certainly more time-consuming than using an automated tool, but the payoff is a deep understanding of a site's architecture. You'll learn exactly how it’s built by saving its core components—HTML for structure, CSS for style, and JavaScript for interactivity—right from your browser.
Forget the simple "Save Page As" command. That usually just spits out a messy, single HTML file with a jumble of disorganized assets. To do this right, you need to think like a digital architect, carefully rebuilding the site's structure on your own machine.
Diving into Developer Tools
Your best friend for this job is your web browser's built-in developer tools. Just right-click anywhere on the page you want to clone and hit "Inspect," or use a shortcut like F12 or Ctrl+Shift+I. This opens up a panel that shows you all the code humming away behind the scenes.
First, head to the "Elements" or "Inspector" tab. This is where you'll find the raw HTML—the skeleton of the website. To grab it all, find the <html> tag at the very top of the code, right-click it, and choose "Copy" > "Copy outerHTML." Now, paste that code into a text editor like VS Code or Notepad++ and save the file as index.html.
This infographic gives you a great visual overview of the manual workflow.
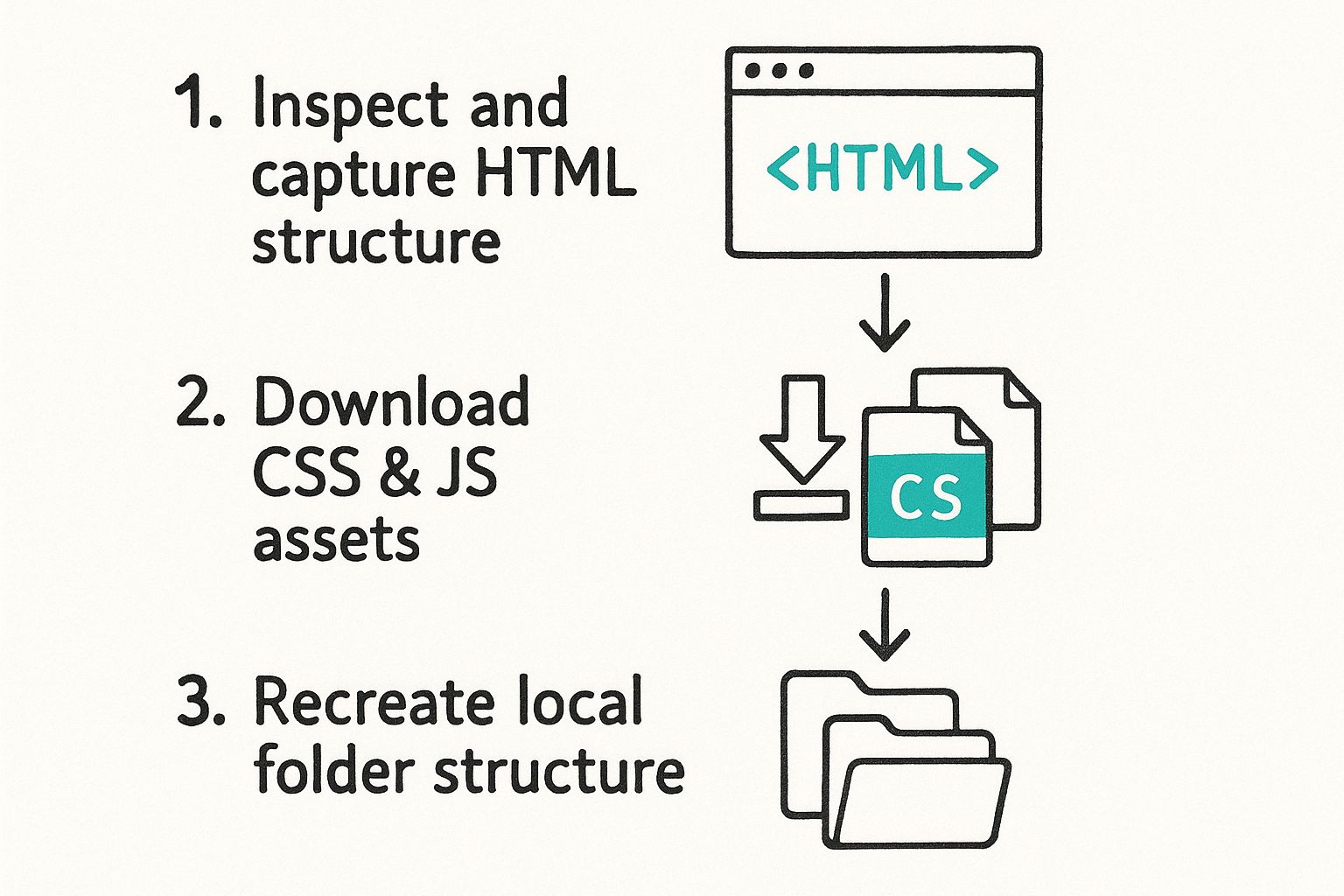
As you can see, it's a methodical process: find the file, download it, and put it in the right place to mirror the live site's structure.
Hunting for Assets
At this point, you have the HTML structure, but if you open it, it'll look completely broken. That's because it's missing all its styling (CSS), interactive features (JavaScript), and images. We call these assets, and you have to track them down one by one.
Jump back into the developer tools and look for the "Network" or "Sources" tab. I find the "Sources" tab is often easier because it presents a clean, folder-like view of every file the page loaded. You'll usually see folders with intuitive names like css, js, and images (or sometimes just assets).
- CSS Files: Find the stylesheets, which always end in
.css. Open each one, copy all the code inside, and save it in a newcssfolder on your computer. - JavaScript Files: Do the same thing for the JavaScript files (ending in
.js), saving them into ajsfolder. - Images: This part is a bit easier. Just find the image files, right-click, and select "Save image as..." to download them into an
imagesfolder.
Manually downloading each component gives you an almost intimate understanding of how modern websites are put together. It’s like deconstructing an engine to learn how it works—a priceless skill for any developer or designer.
Recreating the Folder Structure
The final—and most critical—step is to tie everything together. For your local clone to work, its folder structure has to perfectly match the one on the live server. For instance, if the website's main stylesheet was located at /assets/css/style.css, you need to create an assets folder on your computer, then a css subfolder inside it, and place your style.css file there.
Once your files are organized, open your local index.html file again. You’ll almost certainly need to edit the file paths in the HTML code to point to your local copies. A link that originally looked like <link rel="stylesheet" href="https://example.com/css/main.css"> needs to be changed to something like <link rel="stylesheet" href="css/main.css">.
This process of saving individual resources is fundamental. If you want to dive deeper, you can learn more about how to download files directly from a URL from our related guide. It’s a bit tedious, but it's an incredibly powerful way to learn.
Using Browser Tools for Faster Site Cloning
Going through the manual cloning process is a fantastic way to learn the ropes of web structure, but let's be honest—it's not always practical. When you're up against a deadline or dealing with a complex site, speed and efficiency are what matter most. This is where browser extensions truly shine. They take over the tedious work of hunting down every last file.
Think of an extension as a smart web scraper. It methodically scans a webpage, identifies all the essential pieces—HTML, CSS, JavaScript, images—and bundles them up for you. This is the perfect solution when you need a complete, functional offline copy of a site without spending an hour digging through developer tools. It’s the sweet spot between manual control and full automation.
Getting Started with a Website Downloader Extension
For this guide, I’m going to walk you through a clean and simple tool called Website Downloader. First things first, you'll need to add it to your browser. Just head over to the Chrome Web Store and install it like any other extension. It will pop up in your browser's toolbar, ready to go whenever you need it.
Once it's installed, just go to the webpage you want to clone. Let the page load completely, then click the extension’s icon. A small control panel will appear, giving you a few quick options for the download.
Here’s a look at what the Website Downloader interface looks like when you click the icon.
As you can see, it's a straightforward menu. This is where you'll tell the tool exactly what to grab before starting the download with a single click.
Configuring Your Site Download
The real magic of these tools is in the settings. You're not just saving a single HTML file; you're creating a structured, self-contained replica of the live site.
Here’s a quick rundown of the options you’ll typically find:
- Including Assets: You can usually toggle whether to save images, scripts (
.js), and stylesheets (.css). For a fully working clone, you’ll definitely want to leave all of these checked. - Page Depth: Some downloaders let you follow links and save pages up to a certain "depth." This is handy if you want to grab a small, multi-page site or just one specific section of a larger one.
- Output Format: The extension will almost always package everything into a compressed .ZIP file. This makes the cloned site incredibly easy to manage, store, or send to someone else.
Once you’ve got your settings dialed in, hit the download button. The extension will start fetching all the required assets and organizing them into a neat folder structure inside the ZIP file.
Pro Tip: If you're cloning a media-heavy site, like a photography portfolio or a video blog, do a quick check on your available disk space. Those high-resolution images and videos can add up, and the final ZIP file might be much larger than you expect.
After the download finishes, just unzip the file. Inside, you’ll find a perfectly organized project with folders for HTML, CSS, JavaScript, and all the media. Double-click the index.html file, and it will open the local, offline version of the website right in your browser.
If you want to check out this specific tool, you can find the Website Downloader on its official page.
Troubleshooting Your Cloned Website

Alright, you've downloaded all the files. That’s the easy part done. The real moment of truth comes when you open that local index.html file and… it looks like a disaster. Missing images, plain text with no styling, and links that lead to dead ends are all part of the process. Don't panic. This is almost always due to broken file paths.
When a site is live, it often uses absolute URLs (the full https://example.com/images/logo.png) to find its assets. But for your local copy to work, it needs relative URLs that point to files within its own folder structure (like ./images/logo.png). Your browser is looking for files on the live server instead of in the folder on your hard drive.
Diagnosing and Fixing Broken Paths
So, how do you fix this mess? Your browser's developer tools are your best friend here. Pop them open (usually with F12 or a right-click and "Inspect") and head over to the "Console" tab. You'll almost certainly see a wall of red 404 Not Found errors.
Each error is a clue, telling you exactly which file your browser failed to load. For instance, an error for https://example.com/css/styles.css means the HTML is still hard-coded to grab the stylesheet from the original website.
The fix is surprisingly simple. Open your HTML files in a good text editor—something like VS Code or Notepad++ is perfect—and use its Find and Replace function. This is an absolute game-changer.
- Find:
https://example.com/ - Replace with: (leave this field completely empty)
By replacing the base domain with nothing, you're instantly converting all those broken absolute paths into local, relative ones. One command can fix hundreds of links at once.
Understanding Static Site Limitations
It's also really important to know what a cloned site can't do. What we've created here is a static copy. Think of it as a perfect, high-fidelity snapshot of the website's front end—the HTML, CSS, and JavaScript that a visitor's browser sees and interacts with.
A static clone is invaluable for studying a site's structure, design, and user interface. It captures the entire client-side experience. What it doesn't capture is the backend—the server-side code and databases that power dynamic features.
This means some parts of the site just won't work on your local machine. You’re only getting the tip of the iceberg, not the entire engine room.
Features that will be dead on arrival include:
- Contact Forms: They need a server to actually process and email the form data.
- User Logins: Authentication is a classic server-side job that requires a database.
- Live Search Bars: These almost always query a database to pull results.
- eCommerce Carts: All the logic for adding items and checking out happens on the backend.
Keep these limitations in mind. A static clone is an amazing tool for front-end analysis, but it isn't a fully functioning, transplantable web application.
Ethical Guidelines for Cloning Websites
https://www.youtube.com/embed/Q2yMTcq2OW0
Knowing how to clone a website is a seriously powerful skill. But with great power comes great responsibility, as they say. There's a very clear line between using this knowledge to learn and stepping into unethical—and even illegal—territory.
The golden rule here is incredibly simple: never, ever republish a cloned site as your own.
Think about it. Someone poured their time, creativity, and money into building that website. The design, the code, the content—it's all their intellectual property, and it's protected by copyright law. It's one thing to use a clone for your own education, like picking apart the CSS to see how a cool effect works or studying its JavaScript for inspiration. That's a fantastic way to learn.
But passing it off as your own work or using it for any commercial purpose? That's straight-up plagiarism and can land you in a world of legal trouble.
Respecting Copyright And Intellectual Property
I like to think of a cloned site as a textbook. You can read it, highlight passages, and learn from its examples to get better at what you do. What you can't do is photocopy the whole book, slap your name on the cover, and start selling it. The same logic applies here. Any site you clone should stay on your local machine, for your eyes only.
These protections are the bedrock of the digital economy. With global eCommerce sales expected to soar to $7.5 trillion by 2025, the value of unique digital creations has never been higher. A staggering 85% of consumers worldwide now shop online, so respecting the intellectual property that fuels this massive market is non-negotiable. You can dig into more stats like these in Cimulate.ai's research on digital commerce.
Key Takeaway: Cloning should be for one of two things: personal development or making a legitimate backup of a site you own. Always treat others' intellectual property with the same respect you'd want for your own work.
Heeding The Robots.txt File
Another crucial ethical stop sign is the robots.txt file. This is a simple text file you'll find in a site's main directory (like example.com/robots.txt). It’s the site owner’s way of leaving instructions for web crawlers and other bots, telling them which areas are off-limits for automatic access.
Before you even think about cloning a site, make it a habit to check this file. While your cloning tool might be able to ignore its rules, respecting the owner's explicit wishes is a cornerstone of being a good digital citizen.
If the file says a directory is disallowed, you should honor that. Plowing ahead anyway is a clear signal that you're crossing a line. Sticking to these guidelines ensures you can use site cloning as the valuable learning tool it is, without trampling on the rights of the creators who make the web a vibrant place.
Got Questions About Cloning a Website?
Jumping into website cloning for the first time usually sparks a few questions. You might be wondering about the legal side of things, what the technical limitations are, or which tools are best for the job. It's a good idea to get these things straight before you start.
Let's walk through some of the most common questions people ask. Getting clear on these points will help you handle your project ethically and avoid common pitfalls.
Is It Legal To Clone A Website?
This is the big one, and the answer isn't a simple yes or no. It all comes down to why you're doing it.
If you're cloning a site you own—say, for making a backup or setting up a staging area to test changes—that's 100% legal and a common industry practice. Cloning someone else's site just to study its code for your own personal learning is also generally fine.
The line gets crossed when you try to pass off any part of a cloned site as your own work. Republishing or repurposing someone else's content or design is a direct violation of copyright and intellectual property laws.
The golden rule here is simple: clone for personal learning and development, never to plagiarize.
Can I Clone Any Website?
From a technical standpoint, you can usually grab the front-end code of most websites. A good cloning tool will download the HTML, CSS, and JavaScript that your browser uses to display the page.
But you'll run into trouble with sites built on modern JavaScript frameworks like React or Angular. These sites often load with a bare-bones HTML file and then pull in all the actual content dynamically. A simple downloader might just grab the empty shell, leaving you with a broken, incomplete copy.
Websites that hide content behind a login screen are also a no-go for most basic cloning tools. If a regular visitor can't see it, the tool can't save it.
Will A Cloned Site Work Exactly Like The Original?
Nope, and it's crucial to understand why. A static clone is just a snapshot of a site's front-end—what you see and interact with in your browser. It gets the look and feel right, but that's where it stops.
What it can't do is replicate any of the back-end magic. This means crucial features will be dead on arrival:
- Server-Side Logic: Things like contact forms, user logins, site search, or anything that needs a server to process information won't work.
- Databases: Content pulled from a database, like blog posts or e-commerce product catalogs, will just be static text and images. The clone has no connection to the original database to pull new information.
Think of it like getting a beautiful, high-resolution photo of a car. It looks exactly like the real thing, but you can't get in and drive it. A static clone is perfect for analysis and offline viewing, not for creating a fully functional replica.
Ready to start saving websites for offline use? The Feedforward Software Website Downloader extension offers a one-click solution for archiving pages, doing offline research, or grabbing code for a development project. It’s the easiest way to get the job done securely.
Article created using Outrank
Found this helpful?