How to Clone a Website A Practical Guide

When we talk about "cloning a website," we're essentially talking about making a copy of its front-end files. This means grabbing the HTML, CSS, and JavaScript that make up the site's structure, style, and interactive elements. It's a go-to technique for developers who need to test changes safely, for designers looking to study compelling layouts, and for anyone who needs to back up or move a static site.
Why and When You Should Clone a Website

Before we jump into the how, it’s important to get the why. Learning to clone a website isn't about stealing someone else's work; it’s a core skill in web development. The whole point is to create duplicates of sites you either own or have explicit permission to work on.
Think of it like getting a copy of a building's blueprint before you start knocking down walls. You wouldn't risk renovating the real thing without a plan, right? Cloning gives you that same safe, offline copy to experiment on without any real-world consequences.
The Practical Reasons for Cloning
The need to clone a site pops up all the time in professional settings. Having a perfect replica to mess around with, far away from the live environment where a single mistake can be a disaster, is invaluable.
- Development and Testing: This is the big one. Cloning creates a "staging" environment where developers can test out new features, mess with plugins, or squash bugs without ever touching the live site.
- Creating Backups: A clone is more than just a backup; it's a fully functional snapshot. If your live site ever goes down, you have all the front-end assets ready to go.
- Website Migration: Moving a static site to a new server? Cloning all the files is your first, most important step to make sure nothing gets left behind.
- Design Analysis: I often see designers clone sites just to pick them apart. It's a fantastic way to understand how a complex layout is built or to learn from a really slick user interface.
The core idea is simple: never experiment on your live website. A clone provides a sandboxed environment where you can freely make changes, test functionality, and perfect your updates before pushing them to the public.
This approach has become so fundamental to how we build and maintain websites that it's driving serious market growth. The global Data Clone Software market, valued at roughly $840 million in 2021, is on track to reach $1.35 billion by 2025. According to data on the data clone software market from Cognitive Market Research, this surge is largely due to the rising demand for secure backups and more efficient development workflows. It really shows how cloning has gone from a niche trick to a standard professional tool.
Cloning a Simple Website with Your Browser
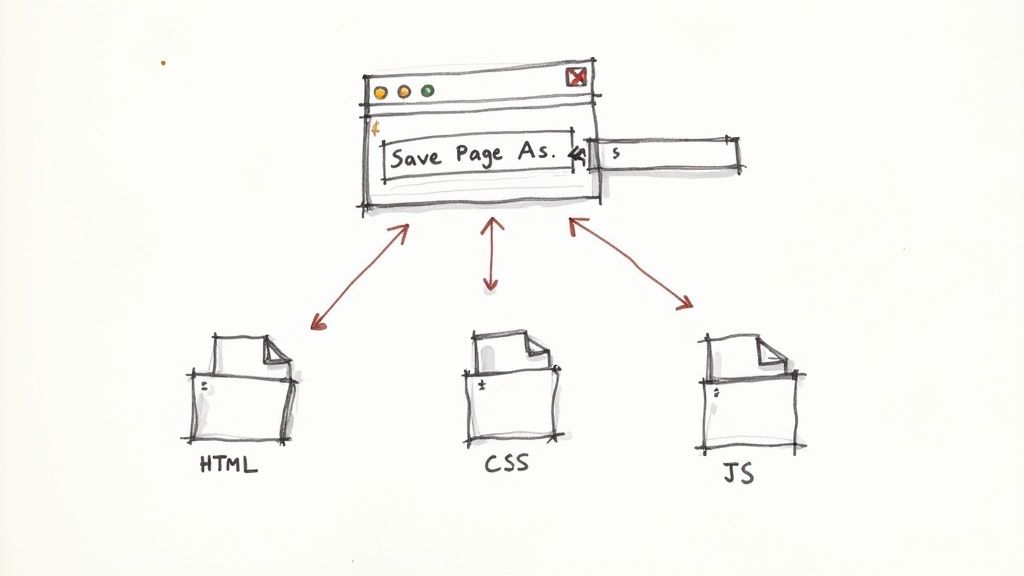
Let's start with the most straightforward method there is: using the web browser you're likely reading this in right now. It's a surprisingly effective way to grab a copy of a simple site, and it’s perfect if you're just starting out and want to see how a webpage is put together.
First, just head over to the page you want to clone. Let it load completely. Then, right-click anywhere on the page and look for the "Save Page As..." option. Depending on your browser—be it Chrome, Firefox, or Edge—the wording might be a little different, but the function is the same. This one command downloads the webpage's core files right onto your hard drive.
When you do this, you’ll end up with an HTML file and a folder with a matching name. That folder is key. It holds all the assets the page needs to display correctly.
What You Get in the Download
If you peek inside that downloaded folder, you’ll see the building blocks of the webpage. It’s a great way to understand how the front-end is structured.
Here’s a quick look at what’s usually inside:
- CSS Files: These are the stylesheets. They dictate everything you see visually—the colors, fonts, layout, and spacing.
- JavaScript Files: These scripts are the engine behind any on-page interactivity. Think image sliders, pop-up forms, or neat little animations.
- Images and Media: Every JPEG, PNG, SVG icon, and other visual element gets saved in here.
Now, if you open that main HTML file in your browser, it will pull all the resources from the folder and render the page on your computer, completely offline. This is a fantastic hands-on way to explore how all the pieces fit together. For more on grabbing specific assets, you can read our guide on how to download files from a URL.
Important Takeaway: The "Save Page As" trick works best for simple, static websites. Think personal portfolios, basic landing pages, or "brochure" style sites. It falls short when dealing with sites that pull content from a database or have complex user interactions.
With an estimated 1.13 billion websites online today, a huge number are built with simple, clean code that this method can capture perfectly. As long as the site delivers its front-end code through standard HTTP requests, you can usually download it directly. You can discover more website statistics on Reboot Online.
Browser Extensions: A Faster, Smarter Way to Clone
While saving a page directly from your browser works in a pinch, it’s a bit of a blunt instrument. The process is slow and notoriously bad at grabbing all the necessary files. For a much cleaner and more reliable result, I always turn to browser extensions. They automate the whole thing, grabbing every file with far greater accuracy and speed.
Think of it this way: instead of manually saving the page and then hunting down missing CSS or JavaScript files, a dedicated tool does the heavy lifting for you. An extension like the Website Downloader for Chrome, for instance, turns a tedious, multi-step chore into a single click. It intelligently scans the page and packages everything up neatly—a real lifesaver for anything more complex than a basic static page.
Getting Set Up With a Cloning Extension
Getting started is as easy as it gets. Just pop over to your browser's extension marketplace (like the Chrome Web Store), search for a website downloader, and add it.
You'll see something like this when you search the Chrome Web Store.

You can check out user ratings and reviews, and then it's just a single click on the "Add to Chrome" button.
Once it's installed, you’ll see a new icon in your browser's toolbar. From there, the workflow is incredibly straightforward:
- Head over to the webpage you want to copy.
- Click the extension’s icon in your toolbar.
- Tell it to start the download from the little pop-up window.
The extension will immediately get to work, downloading not just the core HTML file but also all the dependent assets. This means it grabs the stylesheets, scripts, images, and fonts, then organizes them all into a single, clean folder right on your computer.
Dealing With Dynamic Content and Other Hiccups
Here's where a good extension really shines: handling pages that load content dynamically. You've seen them—sites where new images or articles appear as you scroll. If you use your browser's "Save Page As" feature, you'll miss everything that wasn't visible when the page first loaded. The extension is smarter about this.
My Go-To Trick: Before you click the extension's icon, make sure to scroll all the way to the bottom of the page you want to clone. This simple action forces any "lazy-loaded" elements to appear, ensuring the tool can see and capture them.
Now, if you clone a page and still find that some interactive parts are broken, don't be surprised. This usually happens when a feature relies on server-side code or a database connection. No front-end cloning tool, no matter how good, can access a website's backend. For that level of cloning, you'll need to move on to more advanced, server-side techniques.
Sometimes, a simple browser extension just won't cut it. For complex projects or when you need a complete offline copy of a site, you'll have to reach for more powerful, developer-centric tools. This is where command-line utilities like HTTrack and Wget come into play.
These aren't just page grabbers; they are true website mirroring tools.
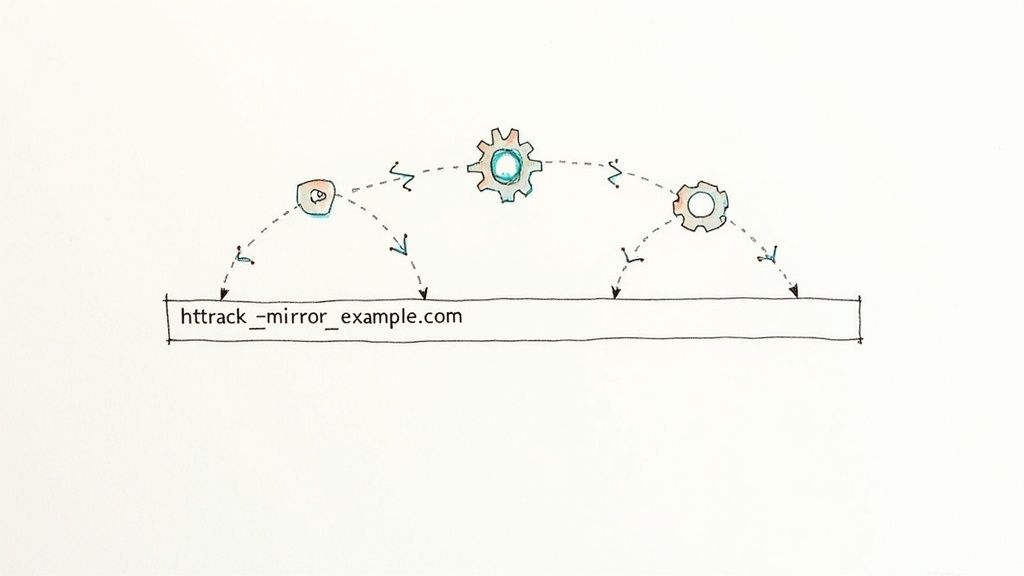
What makes them so powerful is their ability to recursively crawl a website. They start on one page and follow every single link they find, downloading all the associated pages, images, stylesheets, and scripts along the way. This makes them perfect for archiving an entire site or creating a detailed offline version for analysis.
While a tool like the Website Downloader Chrome extension is fantastic for quick, focused captures, HTTrack is the workhorse you need for a full-site mirror.
The Problem With Dynamic Websites
Here’s where cloning gets complicated. Most modern websites, especially e-commerce stores or social media platforms, are dynamic. They don't just serve static files; they build pages on the fly using databases and server-side code to show you personalized content, manage your shopping cart, or handle your login.
When you point a tool like HTTrack at a dynamic site, you’re only capturing the front-end code—the final HTML, CSS, and JavaScript that your browser renders. It’s a perfect snapshot of what a user sees at that moment, but it completely misses the back-end machinery that makes the site work.
A true "clone" of a dynamic website means more than just downloading files. It requires migrating the entire back-end, including the database and server-side applications. That’s a serious undertaking that demands full server access.
The challenge is clear when you look at the scale of online retail. With global e-commerce sales projected to hit $7.5 trillion by 2025, these sites are incredibly complex. Trying to replicate these interactive experiences for testing or analysis is no small feat.
Imagine trying to clone a Shopify store with HTTrack. You'll get the product page layouts and images, sure. But the shopping cart, user accounts, and checkout process? None of that will function because all that logic lives on Shopify's servers.
In these situations, a front-end clone is still incredibly useful for design reviews, competitor analysis, or content backups, but it's crucial to understand you aren't getting a fully functional duplicate.
A Word on Ethics and Legality
Knowing how to clone a website is an incredibly useful skill, but it’s one that comes with serious responsibilities. There’s a golden rule here, and it’s not complicated: only clone websites you own or have explicit, written permission to copy. Straying from that path takes you into a legal and ethical minefield.
When you copy a site without the owner's consent, you're stepping into some risky territory, including potential copyright infringement and intellectual property theft. Think about it—the design, the text, the images, and even the underlying code are all creative works. Taking them without asking is like snatching the blueprints for a custom-built house and building a replica for yourself.
Legitimate Use vs. Malicious Intent
There's a world of difference between using this skill for professional work and using it for something criminal. Cloning a site to test a new design on a staging server, creating a backup of your own work, or migrating a client’s site to a new host are all perfectly valid, everyday tasks for a web professional.
The dark side of this, however, is where things get ugly. Scammers and bad actors use cloning for all sorts of illegal schemes.
- Phishing Scams: A classic tactic is to perfectly clone a bank's login page. The goal is simple: trick unsuspecting people into handing over their usernames and passwords. This is flat-out fraud.
- Selling Counterfeit Goods: It’s common for scammers to duplicate popular e-commerce stores to sell knock-off products or, even worse, just steal credit card details without ever sending a thing.
- Content and Ad Fraud: Some will clone an entire blog or news site, stealing every article and image to pass it off as their own. They then try to cash in on the ad revenue generated from someone else's hard work.
The bottom line is that the tools themselves aren't good or bad—they're just tools. What matters is your intent and whether you have the legal right to copy the website in the first place.
Always err on the side of caution. If you have even a sliver of doubt about whether you have permission, just assume you don’t. It’s a simple principle that will keep you out of hot water and ensure you’re using your skills responsibly.
Answering Your Top Website Cloning Questions
Once you get the hang of cloning a website's front-end, you'll inevitably run into a few tricky situations. I see the same questions pop up all the time, so let's clear the air on some of the most common ones.
Can I Clone a Site That Requires a Login?
This is probably the most frequent question I get. The short answer is, not really—at least not with a simple front-end downloader. These tools see the website just like a new visitor would, which means they get stopped at the login page.
While you could log in yourself and manually save individual pages one by one, there's no automated way to capture an entire members-only area. That kind of access requires a much deeper, server-side approach.
What About SEO and Databases?
People often worry if downloading a site will mess with the original's SEO. Let me put your mind at ease: the act of downloading the files has zero effect on the live website.
The real trouble starts if you upload that clone to a new public domain. Now you've created duplicate content, and search engines like Google really dislike that. It can tank the SEO of your new site. My advice? Keep your clones for private use—like for offline development or creating a staging environment.
The most important thing to understand is that front-end cloning tools cannot access a website's database. This means you're not getting user accounts, e-commerce product lists, or blog posts from a CMS. That’s a full-on site migration, a totally different beast from a front-end clone.
Why Aren't My Forms or Shopping Carts Working?
Another classic "gotcha." You clone a site, open it locally, and find that the contact form or shopping cart is completely broken. Why?
These features rely on server-side code (like PHP or Python) to process information. Your clone is just the static "storefront"—the HTML, CSS, and JavaScript. You've got the look and feel, but none of the "back office" machinery that makes it all work.
For more deep dives into web development topics like these, feel free to check out other articles on the Website Downloader blog.
Ready to start cloning websites with ease? Get the Website Downloader Chrome extension and capture any webpage in a single click. https://websitedownloader.dev
Article created using Outrank
Found this helpful?